Knowhow und Erfahrungen gesammelt in unserem Blog

29.08.2023 Peter Peltzer
![]()
![]()
Zeitreihenvorhersagen finden in vielen Geschäftsfeldern eine Verwendung: Beispielsweise im E-Commerce für die Schätzung der Kundennachfrage, um Lager, Logistik und Absatzmöglichkeiten besser zu planen, oder in der Finanz- und Kreditanalyse, um Zahlungen und Zahlungsausfälle zu analysieren und zu schätzen. Fast immer haben diese Probleme eine Gemeinsamkeit, und zwar, dass ein zukünftiges Ergebnis zum Zeitpunkt der Problemstellung völlig unbekannt ist. Es ist also nur methodisch oder durch Modellierung möglich eine fundierte Schätzung zu generieren. Mithilfe von künstlichen neuralen Netzen lassen sich Modelle kreieren und trainieren, die Vorhersagen treffen können. Inspiriert von den biologischen Zellen unseres Gehirns funktionieren und lernen ANNs auf ähnliche Weise und bilden die treibende Kraft des Deep Learning. Die Klassifizierung von Bildern auf Google Images oder die Texterkennung beim Tippen auf dem Smartphone basieren gleichermaßen auf Deep Learning mit neuralen Netzen.
Ein Perzeptron ist die einfachste Form eines neuronalen Netzes. Es hat einen oder mehrere Eingänge (Inputs) und einen Ausgang (Output). Dazwischen befinden sich einige Variablen und Funktionen, die die Eingangswerte modifizieren und einen Ausgangswert auswerfen. Der Ausgangswert ist der Wert, den das Modell prognostiziert. Das Netz wird trainiert, indem es für schlechte Vorhersagen die Variablen zwischen Eingängen und Ausgängen stärker modifiziert als für gute Vorhersagen. Wie in unserem Gehirn, ist ein Netz bestehend aus nur einem Neuron weder performant noch zuverlässig und kann bei zunehmender Komplexität viele Probleme nicht bewältigen. Die Lösung ist einfach: Multilayer Perzeptron. Man gruppiert mehrere Neuronen in mehreren Schichten. Zwischen Eingangs- und Ausgangsschicht lassen sich beliebig viele Schichten einfügen (Hidden Layer) und jede Schicht ist mit der nächsten verbunden. Jede Schicht, bis auf die des Ausgangs, enthält zusätzlich ein Bias-Neuron, das völlig mit der nächsten Schicht verbunden ist.

Für das Training von MLPs wird ein spezielles Verfahren namens „Backpropagation“ angewendet. Der Algorithmus trifft eine oder mehrere Vorhersagen (Ausgang), indem die Eingänge jede Schicht des Netzes durchlaufen. Dieser Schritt wird auch „forward pass“ genannt. Anschließend wird, per Vergleich mit dem richtigen Ergebnis, der Messfehler ermittelt. Danach werden rückwärts erneut alle Schichten des Netzes durchlaufen (reverse pass) und die Variablen zwischen den Schichten individuell angepasst. Zur Optimierung wird dieser Zyklus beispielsweise so lange wiederholt, bis das Netz nicht mehr dazu lernt oder sich verschlechtert. Diese Optimierungsmethode nennt sich „Gradient Descend“ und ist eine von vielen Optimierungsmethoden.
Die vorgestellten Prognosemethoden mittels ANNs können branchenübergreifend gewinnbringend eingesetzt werden. Beispielsweise können Preise von Immobilien anhand mehrerer Datenattribute wie der Lage und Grundfläche ermittelt werden. Ein Anwendungsgebiet, das wohl einem Großteil der Menschen bekannt sein sollte, ist die Einordnung bestimmter Mails in den Spam-Ordner oder die automatische Markierung der Wichtigkeit des Mail-Inhalts durch Klassifizierungsvorhersage.
Doch was ist mit Systemen, welche autonomes Fahren ermöglichen und die Fahrt- bzw. Flugbahn von Fahrzeugen vorhersagen können, um Unfälle zu vermeiden? Dies ist möglich durch Zeitreihenvorhersage mithilfe von recurrent neural networks, einer weiteren Form von neuronalen Netzen.
RNNs wurden für die Sequenzanalyse und Sequenzvorhersage entwickelt. Sie unterscheiden sich von klassischen feed forward ANNs dadurch, dass die Eingänge nicht nur in eine Richtung (Richtung Ausgabeschicht) laufen, sondern auch wieder zurück bzw. wiederkehrend. Somit behält das Netz die Eingänge im Gedächtnis und verwendet diese immer wieder beim nächsten Kalkulationsschritt. Gleichzeitig versucht es, die nicht relevanten Daten aus dem Gedächtnis zu löschen.
Es gibt drei Arten von Sequenzproblemen:
- One-to-Many
- Many-to-One
- Many-to-Many (auch Sequence-to-Sequence)
Für das Zeitreihenproblem sind die letzten zwei interessant. Bei Many-to-One wird, ähnlich wie bei der Zeitreihenprognose per Autoregression, eine Sequenz an Werten mehrerer Perioden analysiert, um den Wert der nächsten Periode vorherzusagen. Im Fall Many-to-Many werden aus der Sequenz an Eingängen mehrere Ausgänge generiert, die ebenfalls in einer Sequenz angeordnet sind. Dabei muss die Anzahl an Eingängen nicht der Anzahl an Ausgängen entsprechen. Es wäre also möglich, aus einer Zeitreihe bestehend aus 10 Eingängen, die nächsten 2 oder auch die nächsten 20 Ausgänge vorherzusagen. Die Qualität der Ergebnisse nimmt selbstverständlich mit der Anzahl an Ausgängen deutlich ab.
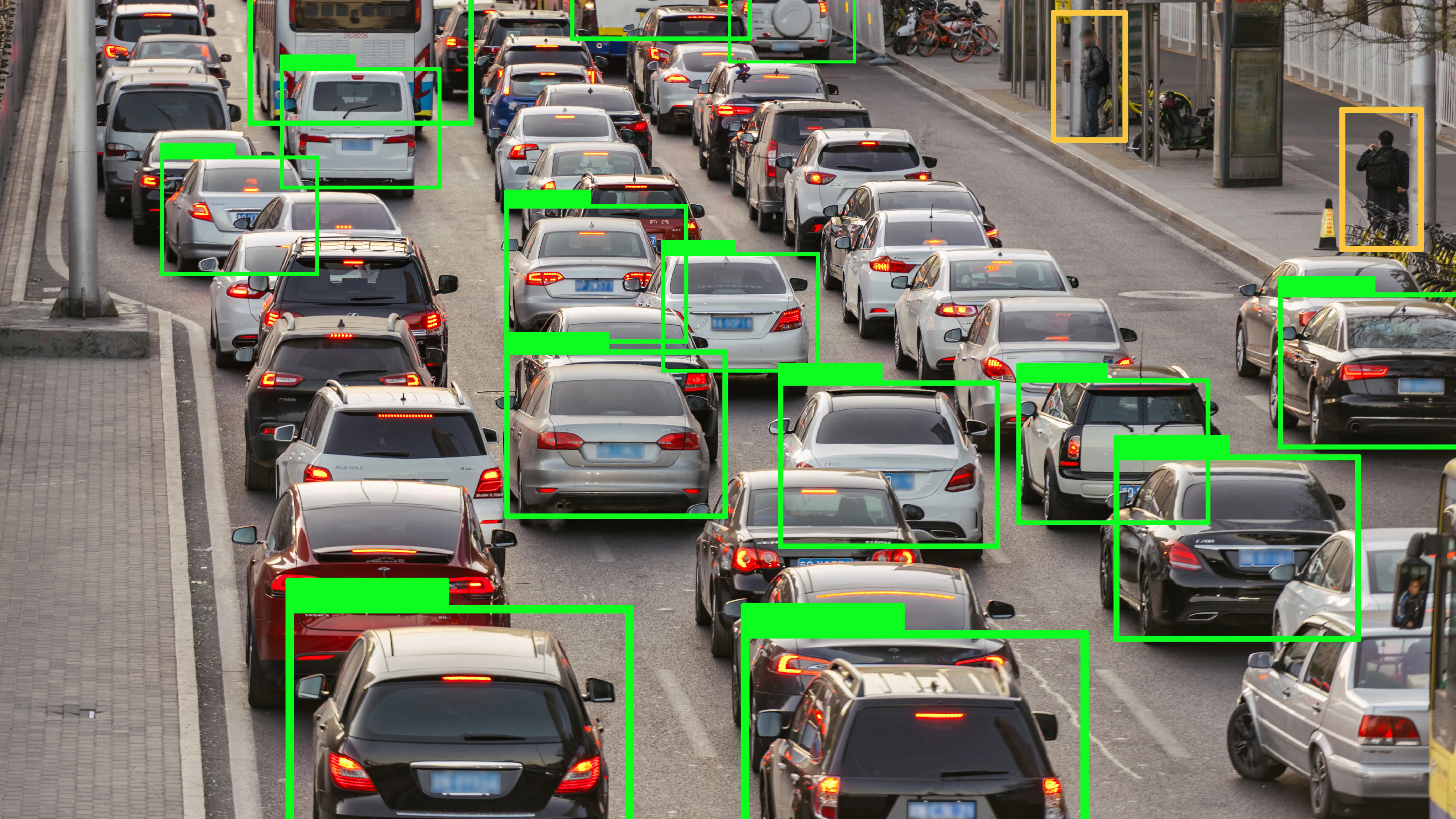
Beim autonomen Fahren kann ein RNN die zukünftige Position und die zukünftige Geschwindigkeit von allen Objekten (Fahrzeuge, Fußgänger etc.) in der nahen Umgebung bestimmen. Diese Informationen vorherzusagen kann einem KI gesteuertem Fahrzeug sicheres und kontrolliertes Fahren ermöglichen. RNNs können aus großen Mengen temporärer Daten lernen. Sie sind aber nicht leicht zu trainieren und erfordern viel Rechenleistung. Außerdem sind sie für tabellarische Daten (z.B. CSV-Dateien) oder Bilddaten nicht geeignet, was den Umgang für viele Unternehmen erschweren könnte. Für weniger komplexe Zeitreihen-Probleme, wie es bei den meisten Unternehmen der Fall sein wird, schießen RNNs wahrscheinlich über das Ziel hinaus.
Es finden sich noch viele weitere Arten von neuronalen Netzen, die hier an der Stelle nicht alle detailliert ausgeführt werden können. Convolutional Neural Networks (CNNs) haben sich beispielsweise für Zeitreihenprobleme als sehr gut bewährt. Sogar simple MLPs können gute Ergebnisse erzielen. Welches Netz am besten eingesetzt werden sollte, ist schwer zu sagen und hängt von dem eigentlichen Problem ab. Für das Zeitreihenvorhersage-Problem gibt es leider keine eindeutige Lösung, welches neuronale Netz am besten performt. Um Absatz- und Lagerprognosen zu treffen, wird ein anderes Modell benötigt, als wenn es darum geht, die harte Landung eines Flugzeugs vorherzusagen. Häufig wird man leider feststellen, dass ein Modell für das eigene Zeitreihen-Problem absolut untauglich ist. Es ist für jeden Problemtypus unterschiedlich. Es ist auch nicht untypisch, mehrere Modelle zu kombinieren und sogenannte Hybrid-Modelle zu kreieren.
Wie findet man also für sich oder für das Unternehmen die geeignete Lösung? Die Antwort lautet Trial-and-Error. Das klingt zunächst deprimierend, doch es ist gar nicht so schlecht wie es sich anhört. Es ist zum Glück nicht notwendig, eigene Modelle „from scratch“ zu bauen. Dank einer Vielzahl an öffentlichen Bibliotheken lassen sich bewährte bestehende Modelle für den eigenen Use-Case finden und visualisieren. Diese Modelle kann man testen und nach Belieben eine Vielzahl an Parametern näherungsweise anpassen, bis es eventuell das eigene Problem löst. Falls sich die Ergebnisse nach der Parameteroptimierung nicht in die gewünschte Richtung bewegen, sollte man eventuell ein anderes Modell versuchen.

Deep Learning mit Hilfe von künstlichen neuralen Netzen ist enorm wertvoll, um Zeitreihenvorhersagen bzw. -prognosen für diverse Unternehmensfragestellungen zu erstellen. Mit Tools wie AutoML lassen sich die für die Netze benötigten optimalen Parameter sogar durch maschinelles Lernen bestimmen. Mit anderen Worten Machine Learning für Machine Learning Modelle. Dies ermöglicht es Machine Learning und Deep Learning praktikabel für Unternehmen umzusetzen, die keine großen Entwickler- und/oder Data Science-Teams zur Verfügung haben. Eine Vielzahl an Visualisierungsmöglichkeiten und Erkennungspotentialen warten darauf, entdeckt zu werden. Man darf sich nicht vor den Begriffen Machine Learning oder Deep Learning abschrecken lassen. Es lohnt sich, diese Technologien auszuprobieren und mit der Performance und den Kosten von aktuell genutzten Technologien zu vergleichen. Falls sich der Einsatz von fortgeschrittener Datenanalyse und – vorhersage noch in der Planungsphase befindet, oder erst begonnen haben sollte, ist der direkte Einstieg in einfache oder komplexe DL-Methoden dennoch problemlos möglich, ohne erst den Erfahrungsweg mit anderen, bzw. älteren Methoden gehen zu müssen.